- 문서 집합에서 주제를찾아내기 위한 기술
- 가정 : "특정 주제에 관한 문서에서는 특정 단어가 자주 등장할 것이다"
- 대표적인 기법
- 잠재의미분석
- 잠재 디리클레 할당 기법
- 잠재 의미 분석(Latent Semantic Analysis)
- 목표 : 문서와 단어의 기반이 되는 잠재적인 토픽을 발견
- 가정 : 문서에 있는 단어들의 분포
- 방법 : DTM행렬에서 단어-토픽 행렬, 토픽-중요도 행렬, 토픽-문서 행렬로 분해
- 잠재 디리클레 할당(Latent Dirichlet Allocation)
- 사용자가 토픽의 개수를 지정해 알고리즘에 전달
- 모든 단어들을 토픽 중 하나에 할당
- 모든 문서의 모든 단어에 대해 단어w가 가정에 의거, $$p(t|d)$$ , $$p(w|t)$$에 따라 토픽을 재할당하고,
- 이를 반복합니다.
데이터준비
앞서 사용한 fetch_20newsgroups를 다시 활용하자
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1,
remove=('headers', 'footers', 'quotes'))
documents = dataset.data
print(len(documents))
>>> 11314
documents[0]
>>> '\Well i'm not sure about the story nad it did seem biased. What
\nI disagree with is your statement that the U.S. Media is out to
\nruin Israels reputation. That is rediculous. The U.S. media is
\nthe most pro-israeli media in the world. Having lived in Europe
\nI realize that incidences such as the one described in the
\nletter have occured. The U.S. media as a whole seem to try to
\nignore them. The U.S. is subsidizing Israels existance and the
\nEuropeans are not (at least not to the same degree). So I think
\nthat might be a reason they report more clearly on the\natrocities.
\n\tWhat is a shame is that in Austria, daily reports of
\nthe inhuman acts commited by Israeli soldiers and the blessing
\nreceived from the Government makes some of the Holocaust guilt
\ngo away. After all, look how the Jews are treating other races
\nwhen they got power. It is unfortunate.\n'전처리
import re
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from gensim.parsing.preprocessing import preprocess_string
nltk.download('stopwords')
def clean_test(d):
pattern = r'[^a-zA-Z\s]' #알파벳만 가져오기기
test = re.sub(pattern, '', d) #패턴에 해당하는거 삭제제
return d
def clean_stopword(d):
stop_words = stopwords.words('english')
return ' '.join([w.lower() for w in d.split() if w not in stop_words and len(w) > 3])
## stopwords에 있는거 버리고,
## w길이가 3미만인거 버리고
## w를 소문자로 만들어서 가져오기
def preprocessing(d):
return preprocess_string(d) #토큰화도 같이 된다.
import pandas as pd
new_df = pd.DataFrame({'article' : documents})
new_df.replace("",float("NaN"), inplace=True)
new_df.dropna(inplace=True)
print(len(new_df))
>>> 11096
##null값을 빼주어서, 데이터프레임의 길이가 줄어들음.
위에서 만든 전처리 함수들을 적용해주자.
##우리가 만든 전처리 함수 적용
new_df['article'] = new_df['article'].apply(clean_test)
new_df['article'] = new_df['article'].apply(clean_stopword)
tokenized_news = new_df['article'].apply(preprocessing)
tokenized_news = tokenized_news.to_list()
drop_news = [index for index, sentence in enumerate(tokenized_news) if len(sentence) <= 1]
news_text = np.delete(tokenized_news, drop_news, axis=0)
print(len(news_text))
>>> 10936
print(drop_news)
>>>[44, 51, 89, 254, 263, 310, 357, 359, 428,...
토픽모델링은 Gensim에서 쉽게 구현할 수 있다.
==================================================================
Gensim 토픽 모델링
우리 데이터에 적용시켜보자.
일단 단어집합의 형태로 바꾸자.
from gensim import corpora
dictionary = corpora.Dictionary(news_text)
corpus = [dictionary.doc2bow(text) for text in news_text]
print(dictionary)
>>> Dictionary(52123 unique tokens: ['act', 'atroc', 'austria', 'awai', 'bias']...)
print(corpus[1]) ##bagofword형태로 바꿈
>>> [(51, 1), (52, 1), (53, 1), (54, 1), (55, 1), (56, 1)...corpus : 말뭉치
잠재의미분석을 위한 LsiModel
from gensim.models import LsiModel
##LDA보다 빠름
lsi_model = LsiModel(corpus, num_topics=20, id2word=dictionary)
topics = lsi_model.print_topics()
몇개 토픽개수를 가지는지 계산을 할 수 있다.
from gensim.models.coherencemodel import CoherenceModel
min_topics, max_topics = 20, 25
coherence_scores = []
for num_topics in range(min_topics, max_topics):
model = LsiModel(corpus, num_topics = num_topics, id2word = dictionary)
coherence = CoherenceModel(model = model,
texts = news_text,
dictionary = dictionary)
coherence_scores.append(coherence.get_coherence())
print(coherence_scores)
>>> [0.4234175791162406, 0.42514443101631455, 0.48428798459278766, 0.5157038056934148, 0.46989403051510353]
## 토픽의 개수를 20개~25개 일때, 각각의 점수.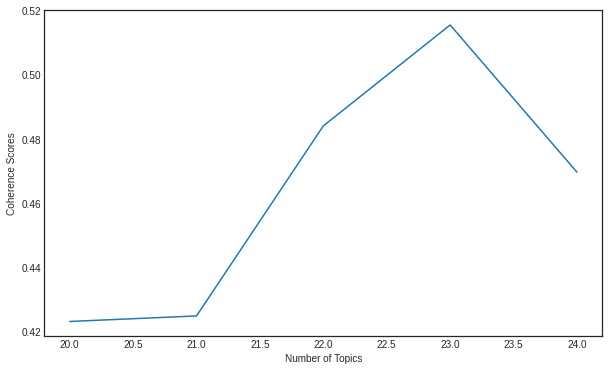
23개 일때가 가장 높다. 토픽의 개수를 23개로 하고, 모델을 다시 돌려서, 어떤 토픽을 가지는지 알아보자
lsi_model = LsiModel(corpus, num_topics=23, id2word=dictionary)
topics = lsi_model.print_topics(num_topics=23)
topics
>>>
[(0,
'0.994*"max" + 0.069*"giz" + 0.068*"bhj" + 0.025*"qax" + 0.015*"biz" + 0.014*"nrhj" + 0.014*"bxn" + 0.012*"nui" + 0.011*"ghj" + 0.011*"zei"'),
(1,
'0.381*"file" + 0.193*"program" + 0.169*"edu" + 0.162*"imag" + 0.130*"avail" + 0.126*"output" + 0.119*"includ" + 0.115*"inform" + 0.101*"pub" + 0.100*"time"'),
(2,
'0.408*"file" + 0.335*"output" + 0.216*"entri" + -0.171*"peopl" + -0.153*"know" + 0.137*"onam" + 0.134*"program" + -0.131*"said" + 0.129*"printf" + 0.115*"char"'),
(3,
'0.249*"imag" + 0.226*"edu" + -0.214*"output" + -0.165*"peopl" + -0.157*"know" + -0.155*"entri" + -0.153*"said" + 0.153*"avail" + 0.142*"jpeg" + 0.124*"pub"'),
(4,
'-0.549*"wire" + -0.223*"ground" + 0.214*"jpeg" + 0.213*"file" + 0.169*"imag" + -0.164*"circuit" + -0.157*"outlet" + -0.139*"connect" + -0.129*"subject" + -0.126*"neutral"'),
(5,
'-0.400*"jpeg" + -0.345*"imag" + 0.276*"anonym" + -0.246*"wire" + 0.160*"privaci" + 0.156*"internet" + -0.151*"color" + 0.144*"post" + 0.125*"inform" + 0.123*"mail"'),
(6,
'0.460*"file" + 0.215*"wire" + -0.169*"output" + -0.158*"program" + -0.154*"edu" + 0.144*"anonym" + 0.141*"firearm" + -0.137*"widget" + 0.123*"jpeg" + -0.120*"entri"'),
(7,
'0.298*"anonym" + -0.286*"file" + 0.247*"imag" + 0.246*"jpeg" + -0.178*"widget" + 0.170*"post" + 0.166*"internet" + 0.155*"privaci" + -0.138*"control" + -0.127*"drive"'),
(8,
'0.295*"hockei" + 0.279*"team" + 0.235*"game" + 0.233*"leagu" + 0.188*"season" + 0.163*"year" + -0.136*"widget" + 0.129*"plai" + 0.128*"space" + -0.122*"anonym"'),
(9,
'-0.500*"drive" + -0.275*"disk" + -0.202*"control" + -0.185*"hard" + -0.168*"bio" + 0.158*"edu" + -0.155*"support" + -0.138*"card" + -0.134*"featur" + -0.119*"scsi"'),
(10,
'0.480*"stephanopoulo" + 0.328*"presid" + -0.238*"drive" + -0.187*"armenian" + -0.183*"peopl" + -0.125*"disk" + 0.123*"packag" + 0.120*"go" + 0.120*"think" + -0.102*"control"'),
(11,
'-0.286*"space" + 0.266*"stephanopoulo" + -0.254*"launch" + 0.213*"drive" + 0.209*"edu" + -0.172*"satellit" + 0.123*"presid" + -0.114*"widget" + 0.113*"disk" + 0.109*"com"'),
(12,
'-0.248*"edu" + 0.232*"widget" + 0.200*"jpeg" + 0.172*"window" + -0.170*"graphic" + 0.161*"convert" + -0.148*"space" + -0.147*"pub" + 0.136*"applic" + 0.133*"hockei"'),
(13,
'0.265*"jesu" + 0.196*"atheist" + 0.189*"edu" + 0.184*"christian" + 0.165*"believ" + 0.154*"god" + 0.145*"exist" + -0.139*"launch" + -0.133*"armenian" + -0.126*"space"'),
(14,
'0.290*"space" + 0.218*"launch" + 0.175*"stephanopoulo" + -0.165*"program" + -0.162*"russian" + -0.159*"govern" + 0.152*"satellit" + -0.147*"administr" + 0.128*"jesu" + 0.123*"post"'),
(15,
'-0.248*"imag" + 0.237*"com" + 0.235*"jpeg" + 0.233*"edu" + -0.224*"data" + 0.218*"launch" + 0.168*"space" + 0.164*"post" + -0.162*"graphic" + 0.146*"anonym"'),
(16,
'-0.238*"south" + -0.219*"rockefel" + -0.204*"secret" + -0.198*"island" + -0.181*"nuclear" + -0.166*"bolshevik" + 0.157*"health" + -0.153*"militari" + -0.143*"ship" + -0.134*"georgia"'),
(17,
'-0.255*"anonym" + -0.222*"edu" + -0.197*"post" + 0.180*"jesu" + 0.170*"pub" + 0.153*"privaci" + -0.149*"imag" + -0.135*"health" + 0.128*"window" + 0.125*"inform"'),
(18,
'0.290*"stephanopoulo" + 0.180*"health" + -0.179*"administr" + -0.161*"govern" + -0.155*"senior" + -0.147*"offici" + -0.147*"russia" + -0.143*"fund" + -0.143*"russian" + -0.123*"think"'),
(19,
'-0.386*"turkish" + -0.314*"jew" + -0.224*"armenian" + -0.202*"jpeg" + -0.197*"turkei" + -0.154*"nazi" + 0.132*"entri" + 0.129*"imag" + -0.129*"drive" + -0.121*"edu"'),
(20,
'-0.265*"turkish" + -0.230*"entri" + 0.228*"edu" + -0.218*"jew" + -0.159*"anonym" + 0.158*"jpeg" + -0.155*"imag" + -0.140*"armenian" + 0.139*"com" + -0.136*"turkei"'),
(21,
'-0.474*"entri" + 0.236*"output" + -0.169*"rule" + 0.143*"jesu" + 0.132*"anonym" + 0.125*"imag" + -0.119*"follow" + 0.118*"avail" + 0.110*"scx" + -0.108*"com"'),
(22,
'0.816*"scx" + 0.276*"gcx" + 0.183*"syx" + 0.179*"mcx" + 0.099*"gyx" + 0.098*"xxi" + 0.096*"uc" + 0.091*"bhj" + 0.091*"chz" + 0.086*"cub"')]
LSA : DTM을 차원축소하여, 축소차원에서 근접 단어들을 토픽으로 묶는다.
이제 그림으로 이해를 해보자.
예를 들어, 행렬A가 있다고 가정하자.
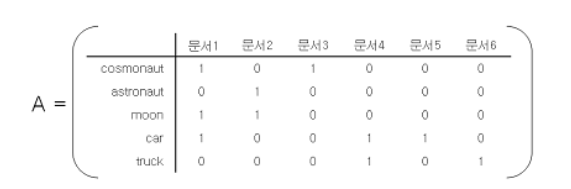
full SVD를 이용해 3개의 행렬로 나누다면, 다음과 같으 형태가 될 것이다.
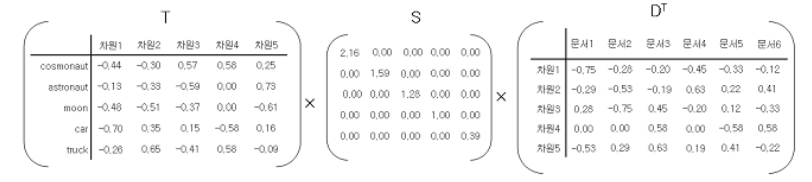
지금은 5차원선에서 예를 들었지만, 현신을 이렇게 아름답지 않다.
현실에선 수만 차원이 될 것이다. 여기서 truncated SVD를 사용해 임의의 값k를 설정하고, k이상의 차원은 없애버리는 방법으로 차원을 축소한다.
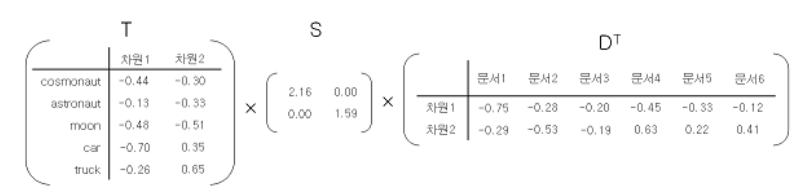
이렇게 형성된 TSDt의 각 요소에 코사인 유사도를 구하면 된다.

정리 :
- LSA는 쉽고 빠르게 구현이 가능하고 단어의 잠재적인 의미를 이끌어 낼 수 있어, 문서의 유사도 계산등에서 좋은 성능을 보여줌
- 하지만, 새로운 데이터를 추가하여 계산하려고 하면 처음부터 다시 계산해야함. (새로운 정보에 대한 업데이트가 어려움.)
- 이것이 최근 LSA대신 word2vec등 단어의 의미를 벡터화할 수 있는 또 다른 방법론인 인공신경망의 방법론이 각광받는 이유..
LDA
LDA : 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다.
LDA.토픽 모델링
일단 이해를 하고 넘어가자.
2개의 문서에 단어들이 있고, 단어별로 해당 토픽이 정해져있다고 가정해보자.
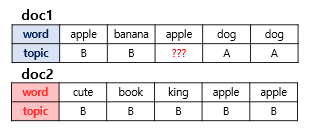
위의 그림은 두 개의 문서 doc1과 doc2를 보여줍니다. 여기서는 doc1의 세번째 단어 apple의 토픽을 결정하고자 합니다.
첫번째로, doc1에서 각 단어들이 어떤 토픽을 가졌는지 보자. 토픽A,B에 50:50의 비율ㄹ로 할당 되어져 있다. 이 기준에 따르면 단어apple은 두 토픽 모두에 속할 가능성이 있다.
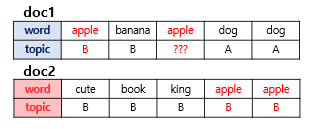
이제 apple이란 단어가 모든 문서에서 어떤 토픽에 해당하는지를 보자. apple은 토픽B에 속할 가능성이 높다.
위 두가지를 참고해서 LDA는 apple이 어떤 토픽에 할당할지를 결정한다.
우리의 fetch_20newsgroups LDA를 구현해보자.
from gensim.models import LdaModel
lda_model = LdaModel(corpus, num_topics=20, id2word = dictionary)
topics = lda_model.print_topics()
topics
>>>
WARNING:gensim.models.ldamodel:too few updates, training might not converge; consider increasing the number of passes or iterations to improve accuracy
[(0,
'0.009*"think" + 0.008*"peopl" + 0.008*"govern" + 0.007*"state" + 0.006*"like" + 0.006*"right" + 0.006*"know" + 0.005*"want" + 0.005*"time" + 0.005*"go"'),
(1,
'0.031*"drive" + 0.014*"disk" + 0.014*"israel" + 0.012*"scsi" + 0.009*"isra" + 0.009*"control" + 0.008*"hard" + 0.008*"problem" + 0.007*"arab" + 0.007*"tape"'),
(2,
'0.008*"file" + 0.007*"anonym" + 0.007*"wire" + 0.005*"post" + 0.005*"work" + 0.004*"connect" + 0.004*"user" + 0.004*"servic" + 0.004*"like" + 0.004*"mous"'),
(3,
'0.011*"plai" + 0.011*"game" + 0.008*"player" + 0.007*"goal" + 0.007*"think" + 0.006*"team" + 0.006*"king" + 0.006*"good" + 0.005*"flame" + 0.005*"right"'),
(4,
'0.010*"health" + 0.008*"medic" + 0.007*"diseas" + 0.006*"patient" + 0.005*"infect" + 0.005*"research" + 0.005*"len" + 0.004*"coli" + 0.004*"test" + 0.004*"studi"'),
(5,
'0.009*"time" + 0.006*"homosexu" + 0.006*"like" + 0.005*"peopl" + 0.005*"car" + 0.005*"smokeless" + 0.004*"think" + 0.004*"group" + 0.004*"year" + 0.004*"nazi"'),
(6,
'0.008*"like" + 0.007*"know" + 0.006*"time" + 0.005*"bike" + 0.005*"good" + 0.005*"think" + 0.005*"want" + 0.005*"ride" + 0.005*"look" + 0.004*"thing"'),
(7,
'0.013*"kei" + 0.010*"encrypt" + 0.010*"secur" + 0.008*"public" + 0.007*"chip" + 0.006*"clipper" + 0.006*"govern" + 0.005*"like" + 0.005*"messag" + 0.005*"phone"'),
(8,
'0.018*"game" + 0.015*"team" + 0.014*"year" + 0.007*"season" + 0.006*"leagu" + 0.005*"plai" + 0.004*"time" + 0.004*"like" + 0.004*"score" + 0.004*"pick"'),
(9,
'0.006*"like" + 0.005*"rate" + 0.005*"copi" + 0.005*"drug" + 0.004*"line" + 0.004*"max" + 0.004*"input" + 0.004*"level" + 0.004*"thank" + 0.004*"know"'),
(10,
'0.016*"output" + 0.016*"entri" + 0.015*"space" + 0.011*"program" + 0.011*"file" + 0.008*"data" + 0.008*"line" + 0.006*"nasa" + 0.005*"check" + 0.005*"window"'),
(11,
'0.010*"work" + 0.009*"like" + 0.009*"card" + 0.008*"time" + 0.008*"problem" + 0.008*"know" + 0.006*"good" + 0.006*"driver" + 0.005*"need" + 0.005*"year"'),
(12,
'0.007*"nist" + 0.006*"ncsl" + 0.006*"gov" + 0.004*"mail" + 0.003*"partit" + 0.003*"address" + 0.003*"email" + 0.003*"quack" + 0.003*"inform" + 0.003*"ciphertext"'),
(13,
'0.008*"armenian" + 0.006*"power" + 0.005*"bike" + 0.005*"condit" + 0.004*"water" + 0.004*"soon" + 0.004*"edu" + 0.004*"mile" + 0.004*"pitt" + 0.004*"gordon"'),
(14,
'0.008*"gun" + 0.007*"presid" + 0.007*"peopl" + 0.005*"nation" + 0.005*"packag" + 0.004*"edu" + 0.004*"includ" + 0.004*"offic" + 0.004*"arm" + 0.004*"senat"'),
(15,
'0.017*"window" + 0.016*"file" + 0.012*"edu" + 0.011*"program" + 0.008*"version" + 0.007*"avail" + 0.007*"softwar" + 0.007*"thank" + 0.007*"mail" + 0.006*"displai"'),
(16,
'0.202*"max" + 0.023*"giz" + 0.019*"bhj" + 0.016*"bxn" + 0.008*"col" + 0.007*"qax" + 0.006*"chz" + 0.005*"nrhj" + 0.005*"nui" + 0.004*"fij"'),
(17,
'0.014*"peopl" + 0.010*"christian" + 0.007*"know" + 0.006*"think" + 0.006*"believ" + 0.006*"jesu" + 0.006*"armenian" + 0.005*"word" + 0.005*"god" + 0.005*"thing"'),
(18,
'0.009*"program" + 0.007*"printf" + 0.006*"rule" + 0.005*"null" + 0.005*"work" + 0.005*"problem" + 0.005*"widget" + 0.005*"entri" + 0.005*"jew" + 0.004*"state"'),
(19,
'0.006*"peopl" + 0.005*"said" + 0.005*"believ" + 0.005*"time" + 0.004*"year" + 0.004*"know" + 0.004*"mormon" + 0.004*"attack" + 0.004*"armenian" + 0.003*"children"')]from gensim.models.coherencemodel import CoherenceModel
min_topics, max_topics = 20, 25
coherence_scores = []
for num_topic in range(min_topics, max_topics):
model = LdaModel(corpus, num_topics = num_topic, id2word = dictionary)
coherence = CoherenceModel(model = model,
texts = news_text,
dictionary = dictionary)
coherence_scores.append(coherence.get_coherence())
print(coherence_scores)
>>> [0.5371599554593046, 0.5298766619832117, 0.5253690123621089, 0.5298870137512938, 0.4903663985140829]
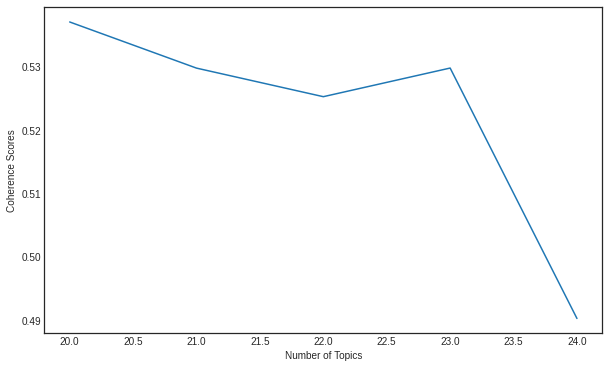
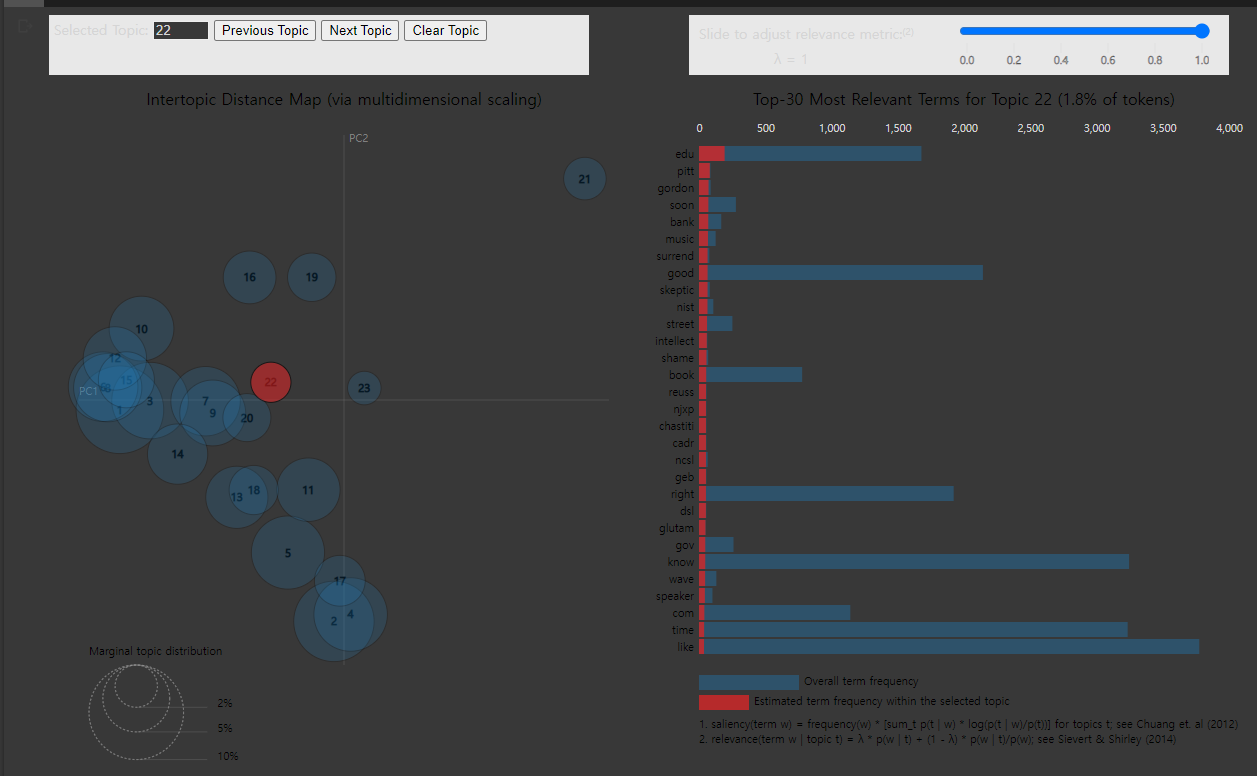
토픽모델링 시각화
!pip install pyLDAvis
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, dictionary)
pyLDAvis.display(vis)