군집분석은 크게 2가지로 나뉜다.
nested성질을 띄는 계층적 군집분석과 partitioned성질을 띄는 비계층적 군집분석이다.

계층적 군집분석(Hierarchical Clustering)

각 관측치를 하나의 최초 군집으로 지정 → 한번에 두개씩 하나의 군집을 만듬 → 모든 군집이 하나의 군집이 될때까지 결합
계층적 군집분석은 분할방법에 따라 응집형(agglomerate)와 분리형(divisive)dmfh 나뉜다.
각각 "bottom-up" , "top-down"형식이다.

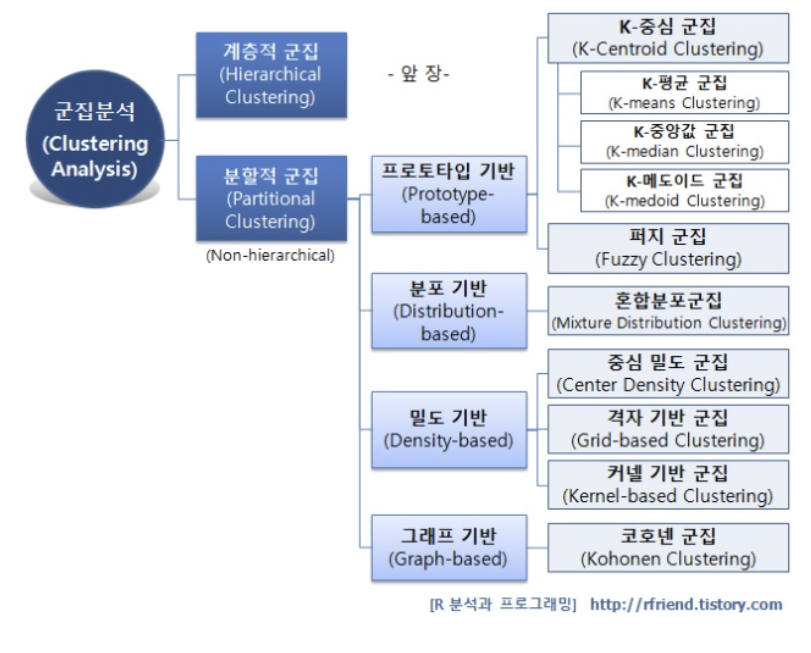
분할적 군집분석(Partitioned Clustering)
처음에 군집수인 k를 지정한 후, 관측치들을 무작위로 k개의 집단으로 분할하고 다양한 기준에 따라 중심값을 수정한다.
이 방식을 반복하며 집단을 재분류한다.
- 분할방법에는 4가지가 있다.
비계층 군집분석에서 대표적은 K-means Clustering알고리즘을 알아보자.
특징
- 사전에 군집의 개수를 정해야한다.
- 클러스터 내 개체를 최대한 비슷하게 만들어야 한다.
- 클러스터 간 차이는 최대화 해야한다.
** 개체와 클러스터 중심사이의 거리 제곱합이 최소가 되도록
개체를 클러스터링에 할당 **
=> 군집내 거리 제곱합이 줄어들수록 유사성이 증가한다.
1. K개의 군집 수 설정
2. 초기 군집에 개체를 할당
- 군집 초깃값은 랜덤 선택, 이에 따라 다른 결과가 나타날지도...
3. 각 개체와 각 군집의 중심사이거리, 가까운 군집으로 재할당
4. 새로운 군집의 중심을 다시 계산한 후, 다시 재할당 여부 판단
5. 재할당이 없을때까지 1~4번 반복
-> 중앙값에 변화가 없을때까지 계속 반복
유사도
1. 코사인 유사도
2. 자카드 유사도
1. 코사인 유사도
코사인 유사도는 다음과 같다.

결과값은 -1과 1 사이의 값을 갖는다. 코사인 유사도는 단어벡터들 간의 각도를 측정해서 유사도를 평가한다.
코사인 유사도의 결과값은 -1(음의 유사관계, 나란히 역방향), 0(벡터가 수직으로 교차), 1(양의 유사관계, 벡터가 나란히 정방향)

2. 자카드 유사도
자카드 유사도는 다음과 같다.
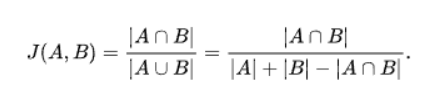
자카드 유사도를 구하는 과정을 예를 들어 설명해보자.
1.) 모든 데이터를 1과 0인 binary형태로 구분한다.
예)
지훈 = [1,1,0,0,1,1,0,0,0]
성민 = [0,1,0,0,1,0,1,0,1]
2.) 지훈과 성민이 겹치는 것을 교집합 : 5
총 개수 : 9
3.) 지훈과 성민이라는 단어 벡터의 자카드 유사도는 5/9
'NLP' 카테고리의 다른 글
| ch4. 문서분류(Document Classification) (0) | 2023.01.24 |
|---|---|
| ch5. 의미연결망 분석(SNA) (0) | 2023.01.21 |
| ch2. 키워드 분석(KeywordAnalysis) (0) | 2023.01.19 |


