이 글은 scikit에서 지원하는 fetch_20newsgroups데이터로 문서분류를 실습하는 코드를 정리한 글이다.
- logistic regression
- 나이브베이즈분류
- SVM
- Decision Tree
- XGBoost
- 정밀도와 재현률
- Gridsearch
에 대한 내용으로 구성되어있다.
데이터준비
- scikit-learn이 제공하는 20개의 주제를 가진 뉴스그룹데이터를 사용한다.
- 텍스트는 CountVectorizer를 거쳐 DTM(Document Term Matrix)행렬로 변환한다.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups()
x = news.data
y = news.target
cv = CountVectorizer()
x = cv.fit_transform(x)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
>>> (7919, 130107) (3395, 130107) (7919,) (3395,)print(x_train[0][0])
>>> (0, 56979) 1
## (0번째문서, n번째 인덱스를 가짐) n번 등장Logistic Regression
- 범주형 변수를 예측하는 모델
특성상 다중 분류에는 적합하지 않음.
- 로지스틱은 회귀의 뼈대가 되는 아이디어다.
- 실제 많은 자연, 사회현상에서 특정변수에 대한 확률값이 선형이 아닌 S-커브 형태를 따르는 경우가 많음.
이러한 S-커브를 함수로 표현한것이 바로 로지스틱 함수. 딥러닝에선 sigmoidg함수라고 불리기도 한다.
- 이 시그모이드 함수는 어떤 값이든 입력값으로 사용할 수 있지만, 출력결과는 항상 0과 1사이 값이 된다.

코드로 돌아와서 파이썬에서 구현해보자.
20개의 뉴스주제(즉, 20개의 클래스)가 있기 때문에 적합하진 않다.
from sklearn.metrics import accuracy_score #평가기준 임포트
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(x_train, y_train)
pred = LR.predict(x_test)
acc = accuracy_score(pred, y_test)
print(acc)
>>> 0.873...
나이브 베이즈 분류기(Naive Bayes Classification)
- 베이즈 정리를 적용한 확률적 분류 알고리즘
- 모든 특성들이 독립임을 가정(naive 가정)
- 입력 특성에 따라 3개로 분류
====================================================================
1. 가우시안(Gaussian) 나이브 베이즈 분류기 : 설명변수가 연속형 변수(수량화가능한 변수)일때 사용
1.) 가정 : 정규분포 하에서 베이즈 정리를 사용
2.) 정규분포를 가정한 표본들을 대상으로 조건부 독립을 나타내, 항상 같은 분모를 갖는 조건하에서,
분자의 값이 가장 큰 경우, 즉 확률이 가장 높은 경우를 선택하는 것!!
정규분포식에서

y = c에서 X = x의 정규분포의 표현식이 위와 같다.
이것을 풀어말하면 밑과 같다.

조건부 독립으로 표현하면

분모는 항상 같으므로, 분자만 비교를 하자. (분류모델의 선택편의를 위해서)
1과 2가 같은 식은 아니지만, 동일한 조건에서 분모만 제외시킨 식이다.

최종식은 위와 같다. 조건부 독립에 정규분포를 대입
2. 베리누이 나이브 베이즈 분류기 : 설명변수가 범주형이고 범주가 2개 밖에 없을때 사용
1.) x = 0,1
2.) 조건부 확률은 이렇게 표시된다.

3.) 여기서 좌항과 우항이 같진 않지만, 분모는 항상 동일하기 띄기 때문에 무시

4. ) 다항분포를 사용한 범주형 조건부 확률을 구할 수 있다.

3. 다항(Multinomial) 나이브 베이즈 분류 : 설명변수가 범주형 변수(이름, 성별..)일때
========================================================================
베이즈 정리에 대해 알아보자.
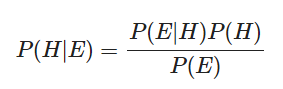
$$P(H)$$ 는 사전확률, $$P(H|E)$$는 사후 확률이라고 한다.
베이즈 정리는 근본적으로 사전확률과 사후확률 사이의 관계를 나타내는 정리이다.
결론부터 말하자면, 베이즈 정리는 새로운 정보를 토대로 어떤 사건이 발생했다는 주장에
대한 신뢰도를 갱신해 나가는 방법이다.
- 베이즈 정리 : 통계학의 근본적인 패러다임을 바꾸었다.
기존 통계 : '빈도주의'관점
→ 확률공간(모집단 혹은 표본집단)을 정의해 놓고 그 뒤에 계산을 통해 생기는 결과물을 수용하는 패러다임
베이지안 관점의 통계(연역적 추론)
→ 사전 확률과 같은 경험에 기반한 선험적인, 혹은 불확실성을 내포하는 수치를 기반으로 추가 정보를
바탕으로 사전확률을 갱신(귀납적 추론)
문제해결을 통해 베이지안 통계방법을 이해해보자.
질병 A의 발병률은 0.1%로 알려져있다. 이 질병이 실제로 있을 때 질병이 있다고 검진할 확률(민감도)은 99%, 질병이 없을 때 없다고 실제로 질병이 없다고 검진할 확률(특이도)는 98%라고 하자.
만약 어떤 사람이 질병에 걸렸다고 검진받았을 때, 이 사람이 정말로 질병에 걸렸을 확률은?
Solution
Hypothesis(가정) : True. 실제로 병이 있다.
Evidence(전제) : 병이 있다고 진단을 받음
따라서, 기본적으로 질병 A의 발병률은 0.1%이므로 임의의 사람이 이 질병에 걸렸을 확률은 로 쓸 수 있으며, 이다.(True Positive)
질병이 있다고 진단 질병이 없다고 진단

이제 P(H|E)를 P(E)와의 관계로 알아보자.
위에서 한 베이즈 정리를 통해

이렇게 풀 수 있고, 우리가 구하고자 하는 P(H|E)를 계산하면

이 값을 얻을 수 있다.
신뢰도를 갱신해 나가는 방법에 대해서는 아래의 링크에서 자세하게 설명한다.
https://angeloyeo.github.io/2020/01/09/Bayes_rule
베이즈 정리의 의미 - 공돌이의 수학정리노트
angeloyeo.github.io
DTM을 이용한 Naive Bayes
- fetch_20newsgroups에서는 클래스가 20개이므로 다항 나이브베이즈 분류기를 사용해야함.
from sklearn.naive_bayes import MultinomialNB
NB = MultinomialNB()
NB.fit(x_train, y_train)
pred = NB.predict(x_test)
acc = accuracy_score(pred,y_test)
print(acc)
>>> 0.8309278350515464
위의 정확도를 저번에 배운 tf-idf를 통해서 향상시켜주자
tf-idf를 이용한 정확도 향상
from sklearn.feature_extraction.text import TfidTransformer
##x_train과 x_test를 tf-idf로 바꿔주기
tfid = TfidTransformer()
x_train_tf = tfid.fit_transform(x_train)
x_test_tf = tfid.fit_transform(x_test)
##바꾼것으로 학습하기
NB.fit(x_train_tf, y_train)
pred = NB.predict(x_test_tf)
acc = accuracy_score(pred, y_test)
print(acc)
>>>0.8394698085419735
#### 크진 않지만, 정확도가 거의 0.9%향상된 모습을 볼 수 있음.
Support Vector Machine(SVM)쉽게 이해하기
- 분류 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델.
- 결정경계 즉, 분류를 위한 기준 선을 정의하는 모델이다.
분류되지 않은 새로운 점이 나타나면 경계의 어느쪽에 속하는지 확인해서 분류과제를 수행할 수 있다.
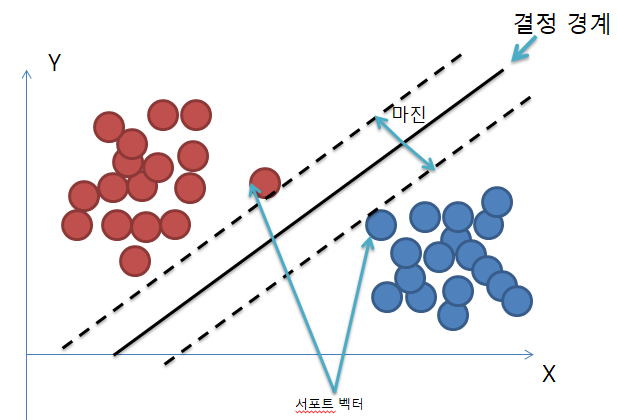
결정경계는 데이터 군으로부터 최대한 멀리 떨어지는게 좋다.
★ 최적의 결정경계는 마진을 최대화 한다★
- 학습 방향 : 마진을 가장 크게하는 방향으로 학
- support vector : 결정경계와 가장 가까이 있는 원소에서의 벡터
- Margin : 결정경계와 서포트 벡터사이의 거리
SVM의 장점 : 속도가 빠르다
- 원리 : 대부분의 머신러닝 알고리즘은 학습 데이터를 모두 사용해서 모델을 학습하지만,
SVM은 결정경계를 정의하는게 결국 서포트 벡터이기 때문에, 데이터포인트 중에서 벡터만 잘 골라내면
나머지 쓸데 없는 수많은 데이터 포인트들을 무시할 수 있다. → 그래서 빠르다!!!
※주의사항※
- 마진의 최대화하면서 학습을 해야하는데, 결국 이상치(Outlier)를 잘 다루는게 중요하다.
이상치를 잘 활용하자!!

아웃라이어 : 왼쪽에 혼자 튀어 있는 파란 점과, 오른쪽에 혼자 튀어 있는 빨간 점
- 아웃라이어를 허용하지 않고, 기준을 까다롭게 세움. 하드마진(hard margin)이라고 함.
▶서포트벡터와 결정경계사이의 거리가 매우 좁다. = 마진이 작다. : 개별적은 학습 데이터를 다 놓치지 않으려고 이상치를 전부 허용하면, 테스트 데이터를 돌릴때, 오버피팅 발생!!
따라서 다음그림과 같이 이상치들을 어느정도 마진안에 포함시켜서 서포트벡터를 너그럽게 기준을 잡아야한다.
이것을 (soft margin)이라고 한다. 너무 대충대충하면 언더피팅이 있을수 있으니 주의하자
검색결과 :
따라서, sklearn-learn을 사용하자!!
예제로 먼저 공부해보자.
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear')
training_points = [[1, 2], [1, 5], [2, 2], [7, 5], [9, 4], [8, 2]]
labels = [1, 1, 1, 0, 0, 0] #1 : 빨간색, 0: 파란색
classifier.fit(training_points, labels) #학습데이터와 레이블을 넣어주기
##어떻게 분류되었는지 확인하기
print(classifier.predict([[3, 2]]))
>>> [1]
##서포트벡터 확인
print(classifier.support_vectors_)
>>> [[7. 5.]
>>> [8. 2.]
>>> [2. 2.]]
파라미터 조절
- C : 이상치를 어느정도 허용할 것인지, 서포트벡터를 얼마나 유연하게 그을건지 결정
(기본값 : 1)(값이 클수록 하드마진(이상치 허용X), 작을수록 소프트마진(이상치 허용O))
#당연히 C의 최적 값은 데이터에 따라 다르다. 결국 여러가지 C값을 넣어보면서 모델을 검증하는 수밖에 없다.
- kernel : 직선으로는 결정경계를 그을 수 없는 상황에서, 결정경계 선의 유형을 바꿔주기
# 'poly' : 다항식
# 'RBF' : 기본값 : radial bias function(called 가우시안 커널)
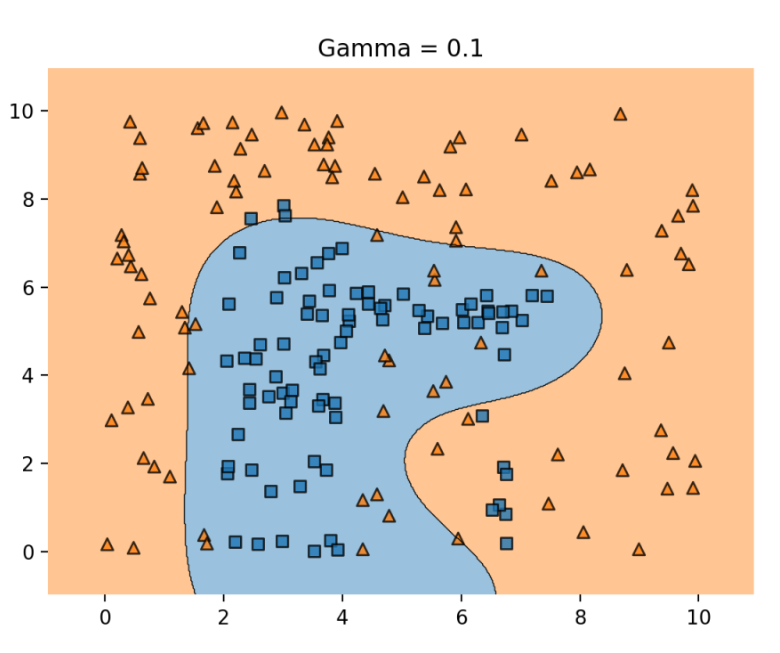
- gamma : 결정 경계를 얼마나 유연하게 그을 것인지 결정
C와 비슷한 개념
값이 클수록 결정경계가 구불구불 -> 오버피팅 초래, 너무 정확하게 그림
값이 작을수록 직선에 가까워짐 -> 언더피팅 초래, 너무 대충 그림
 |
classifier = SVC(kernel = "rbf", C = 2, gamma = 0.5)
##이런식으로 함
Decision Tree
- 분류와 회귀에 사용되는 지도 학습 방법
- 데이터 특성으로 부터 추론된 결정 규칙을 통해 값을 예측
- if-then-else 결정규칙을 통해 데이터 학습
- 트리의 깊이가 깊을수록 복잡한 모델

질문을 던져나가면서, 학습하는 방식
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
DT = DecisionTreeClassifier()
DT.fit(x_train, y_train)
pred = DT.predict(x_test)
acc = accuracy_score(pred, y_test)
print(acc)
>>> 0.6185567010309279
Boosting
- 여러개의 약한 Decision Tree를 조합해서 사용하는 Ensemble기법중 하나.
1. ,약한 예측 모형들의 학습 에러에 가중치를 두고, 순차적으로 다음 학습 모델에 반영
2. 강한 예측모형을 만들수 있음.
XGBoost란?
- Extreme Gradient Boosting의 약주
- Boosting기법을 이용하여 구현한 대표적 알고리즘(Gradient Boost)를 병렬학습이 지원되도록 구현한 라이브러리.
장점
- 병렬처리로 학습, 분류 속도가 빠르다.
- 과적합 규제(regularization)
- GBM은 과적합 규제가 없으나, XGBoost는 자체에 과적합 규제 기능으로 강한 내구성을 지님.
- Early Stopping(조기종료)기능이 있음.
내용이 너무 많아서, 자세한 내용은 우노님의 블로그를 참고하도록 하자.
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimtors = 30,
learning_rate=0.05,
max_depth = 3)
xgb.fit(x_train, y_train)
pred = xgb.predict(x_test)
acc = accuracy_score(pred, y_test)
print(acc)
>>> 0.7737849779086893
교차검증
- 일반 검증은 학습 데이터가 테스트 데이터로 사용되지 않음
- 교차 검증은 데이터를 n개의 집합으로 나누어 정확도를 계산해 학습 데이터로 사용된 데이터도 테스트 데이터로 사용
- 교차 검증을 사용하면 일반 검증보다 모델의 일반화가 잘 되어 있는지 평가 가능
##앞에서 구성한 나이브베이즈모델로 교차검증을 진행해보자.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(NB,x,y,cv=5)
print(scores, scores.mean())
>>> [0.83870968 0.83826779 0.82368537 0.83031374 0.83642794] 0.833480903927519
정밀도와 재현률

- 정밀도(precision) : 양성클래스가 정답으로 예측한 샘플이 실제로 양성일 클래스일 확률을 의미
(예측 Postived에서 실제 Postive로 예측한 확률)
- 모델이 얼마나 양성클래스를 잘예측하는지를 나타냄
- 재현율(recall) : 실제 양성에서 양성으로 예측한 확률
- 모델이 얼마나 실제를 잘 예측하는지를 나타냄

정밀도와 재현율의 가중조화평균인 F1-score라는 지표는 정확도보다 더 효과적은 모델 분석지표로 알려져있다.
대표적으로 imbalanced data일때, 효과적으로 접근할 수 있다.
예를 들어 이해해보자.
웹사이트에서 판매량 데이터분석을 하고 있다고 가정하자. 98%의 방문자들은 물건을 사지않고, 2%의 방문자들만 물건을구입한다. 여기서 어떤 방문자가 물건을 구입하고 어떤 방문자가 보기만 하는지 분류하는 모델을 개발한다고 가정하자.
모델이 정확도로 내놓은 값은 모든 방문자가 보기만하는 사람들이라고 예측한다. 이는 현실에선 쓸모없는 모델이 분명하다.
imbalanced dataset에서는 정확도는 좋은 평가지표가 아니다. 이때, F1-score를 통해 문제를 해결할 수 있다.
이상적인 모델은 산사람(2%)과 안사람(98%)을 제대로 분류하고, 산사람(2%)중에서 산사람으로 분류한 비율을 제대로 알아야한다.

- 결론적으로 F1-score는 precision과 recall이 모두 높으면 높고, 0.0~1.0사이의 값을 가진다.
- 모두 looker로 분류한 모델을 Accuracy(정확도)로 평가하면 99%의 정확도라는 썩 괜찮은 모델같지만, F1 score로 평가하게 되면 0이 나온다. 좋지 않은 모델이라는 것을 판단할 수 있게 되었다.
다중 클래스 분류 문제에서 정밀도와 재현률을 계산할때는, 클래스간의 지표를 어떻게 합칠지를 지정해야한다.
1. None : 클래스간 지표를 합치지 않고 그대로 출력
2. micro : 정밀도와 재현률이 같음.
3. macro : 클래스간 지표를 단순 평균한 값
4. weighted : 클래스간 지표를 가중 평균한 값
f1-score의 클래스간 평기지표를 구분하는 내용에 대해 자세한 내용은 예제와 함께 Godspeed님의 블로그를 참조하자.
깔끔한 예제와 명쾌한 설명이 들어있어 읽기 편하다.
https://dhlee-study.tistory.com/2
[평가지표 정리] F1-score, Macro f1-score, Micro f1-score
각 지표는 처음 보는 분들에게 혼돈이 될 것입니다. 글로 설명된 내용을 읽어서 이해하기 보다는 간단한 예제를 따라 풀어보면서 지표를 이해하는 것이 도움이 될 것입니다. 다 범주에서 실제값
dhlee-study.tistory.com
GridSearch를 이용한 파라미터 최적화
일단 나이브베이즈 분류기는 alpha파라미터를 통해, Laplace Smoothing을 설정할 수 있다. 클래스를생성하고 fit 메서드에 설명변수 행렬 X와 라벨y를 차례대로 넣어주면 된다.
여기서 laplace smoothing을 소개해보자.
- 일단 smoothing이란 확률값잉 0이 되지 않도록 문장 생성확률이 정의되지 않는 문제를 해결하기 위한 방법이다.
간단하게, 나이브 베이즈 값을 구할때, 값이 0이 되지 않게 분모에 alpha만큼 구하게 되는 것이다.

위의 식과 같이 V만큼 더해주는 것을 말한다.
얼마나 더해주는지에 따라 성능의 차이가 나는데, 모델에서 이것을 파라미터로 지정을 하고있다.
from sklearn.model_selection import GridSearchCV
GS = GridSearchCV(estimator=NB, param_grid={
'alpha' : [0.001, 0.01, 0.1, 1.]},
scoring = 'accuracy',
cv = 10
)
GS.fit(x_train, y_train)
print(GS.best_score_)
>>> 0.8754879707313336
print(GS.best_params_)
>>> {'alpha': 0.001}from sklearn.model_selection import GridSearchCV
GS = GridSearchCV(estimator=NB, param_grid={
'alpha' : [0.001, 0.002, 0.003, 0.0005]},
scoring = 'accuracy',
cv = 10
)
GS.fit(x_train, y_train)
print(GS.best_score_)
>>> 0.8763716494911187
print(GS.best_params_)
>>> {'alpha': 0.0005}
'NLP' 카테고리의 다른 글
| ch5. 의미연결망 분석(SNA) (0) | 2023.01.21 |
|---|---|
| ch3. 군집분석 (0) | 2023.01.19 |
| ch2. 키워드 분석(KeywordAnalysis) (0) | 2023.01.19 |


